2 minute
Video Preview

ArXiv
Preprint
ECCV 2020
Oral
Presentation
Slides
Source Code
Github
Demo Colab
Notebook
Can the Rules in a Deep Network be Rewritten?
Deep network training is a blind optimization procedure where programmers define objectives but not the solutions that emerge. In this paper we ask if deep networks can be created in a different way. Can the rules in a network be directly rewritten?
Original Model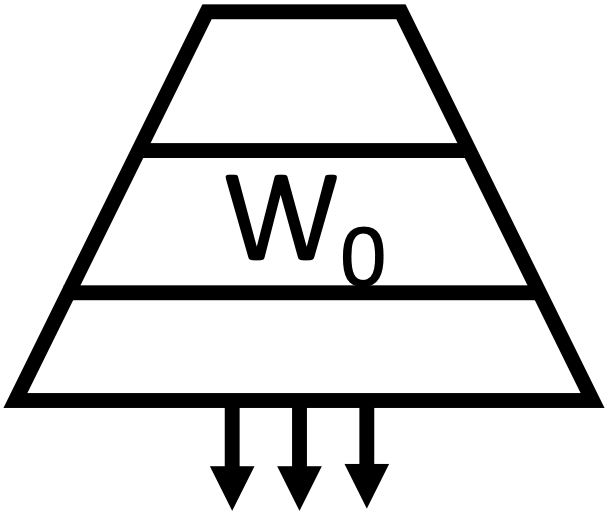 |
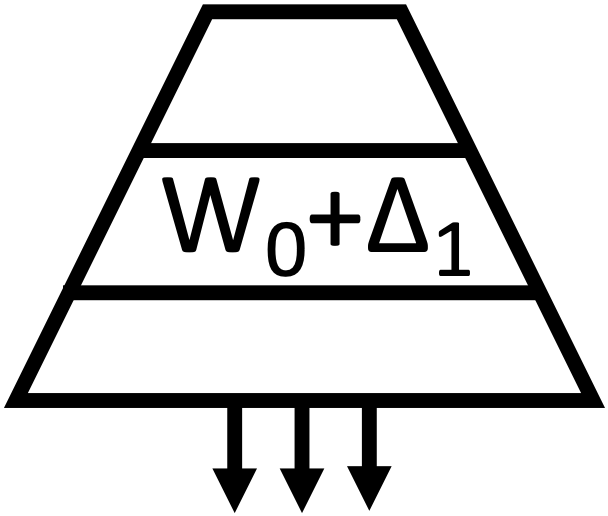 |
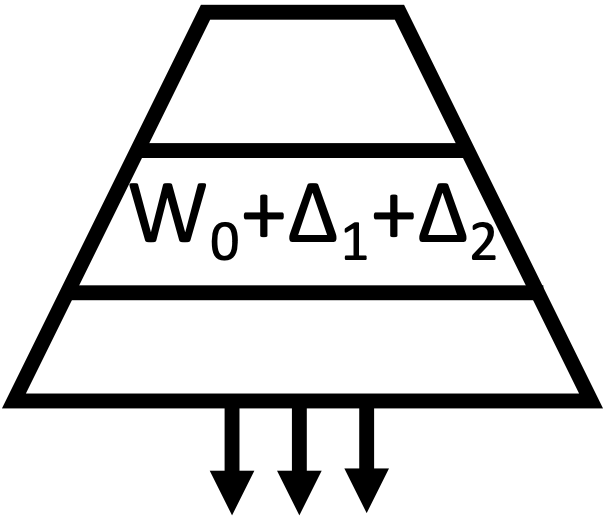 |
 |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Why Rewrite a Model?
There are two reasons to want to rewrite a deep network directly:
- To gain insight about how a deep network organizes its knowledge.
- To enable creative users to quickly make novel models for which there is no existing data set.
Model rewriting envisions a way to construct deep networks according to a user's intentions. Rather than limiting networks to imitating data that we already have, rewriting allows deep networks to model a world that follows new rules that a user wishes to have.
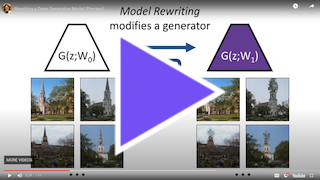
What is Model Rewriting?
Model rewriting lets a person edit the internal rules of a deep network directly instead of training against a big data set.
The difference between training and rewriting is akin to the difference between natural selection and genetic engineering. While training allows efficient optimization of a global objective, it does not allow direct specification of internal mechanisms. In contrast, rewriting allows a person to directly choose the internal rules they wish to include, even if these choices do not happen to match an existing data set or optimize a global objective.
Rewriting a model is challenging, because doing it effectively requires the user to develop a causally correct understanding of the structure, behavior, and purpose of the internal parameters of the network. Up to now it has been unknown whether direct model rewriting is a reasonable proposition.
Our paper shows that model rewriting is feasible.
Video
This 10 minute talk demonstrates the user interface and gives an overview of the mathematical ideas.
The mp4 files of the videos can be downloaded directly:
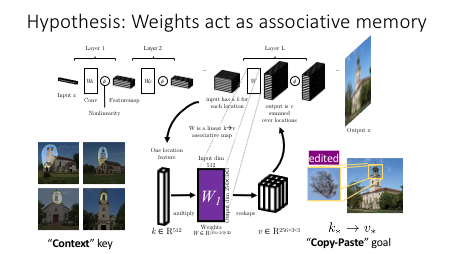
The Connection to Associative Memory
Our method is based on the hypothesis that the weights of a generator act as Optimal Linear Associative Memory (OLAM).
OLAM is a classic single-layer neural data structure for memorizing associations that was described by Teuvo Kohonen and James A Anderson (independently) in the 1970s. In our case, we hypothesize that within a large modern multilayer convolutional network, the each individual layer plays the role of an OLAM that stores a set of rules that associates keys, which denote meaningful context, with values, which determine output.
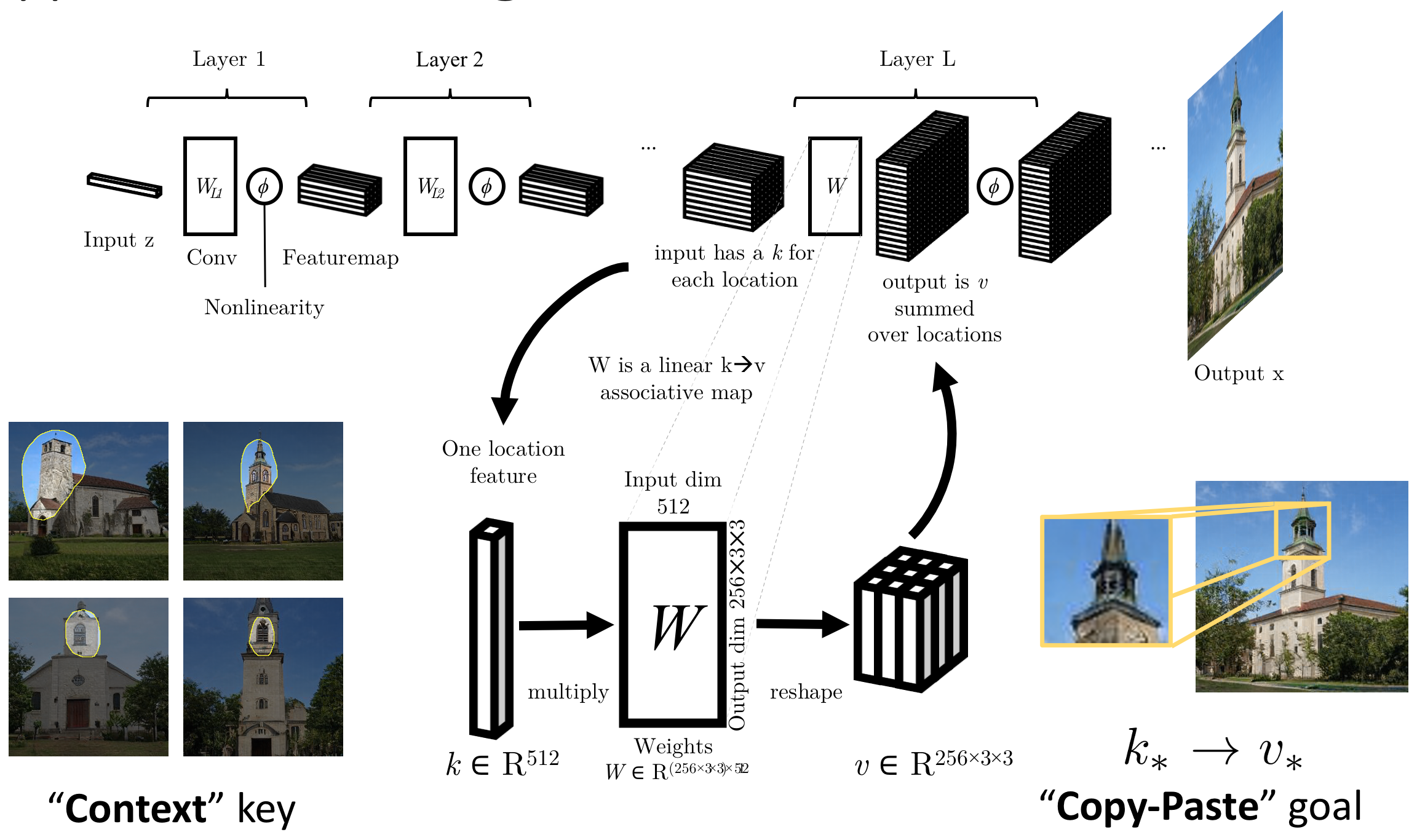
The implication of the optimality hypothesis is that an individual memorized rule is stored within the weights in a slot corresponding to a particular subspace of rank-one updates determined by the fixed global key statistics and the context (key) of the rule being changed — but not the value.
In other words, one rule corresponds to a line of memory that can be rewritten freely.

Therefore, to alter a rule, we first identify the subspace direction d corresponding to one specific rule's memory slot, then we make a change in that direction to achieve the desired change. Since the update direction minimizes interference with other rules, one rule can be changed dramatically to fit any goal the user wishes to specify, while leaving the rest of the model's behavior essentially unchanged.
The reasoning is discussed further in the talk, and full details are described in the paper.
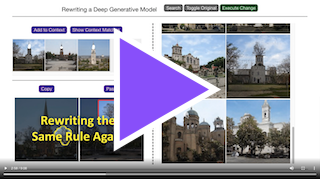
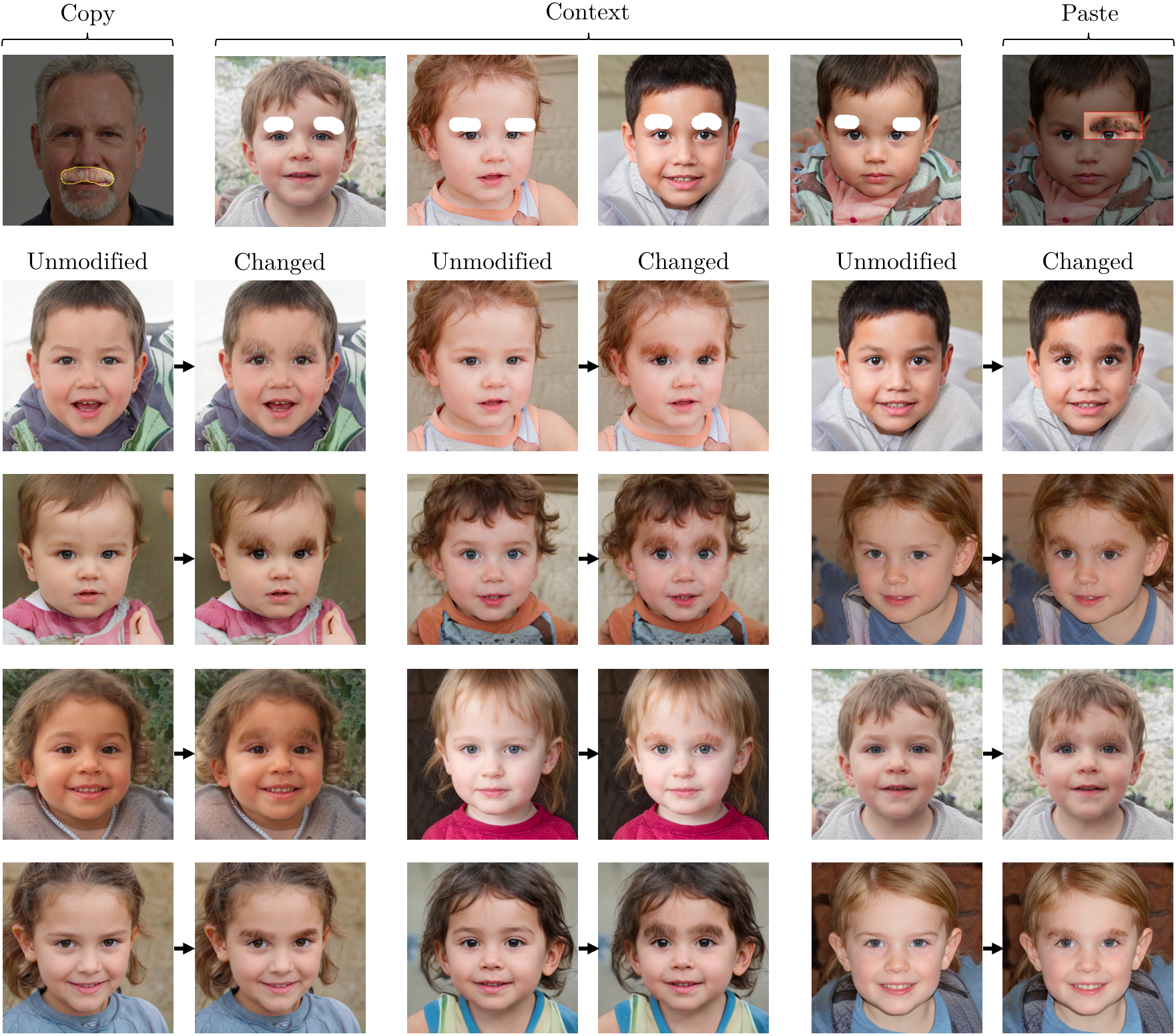
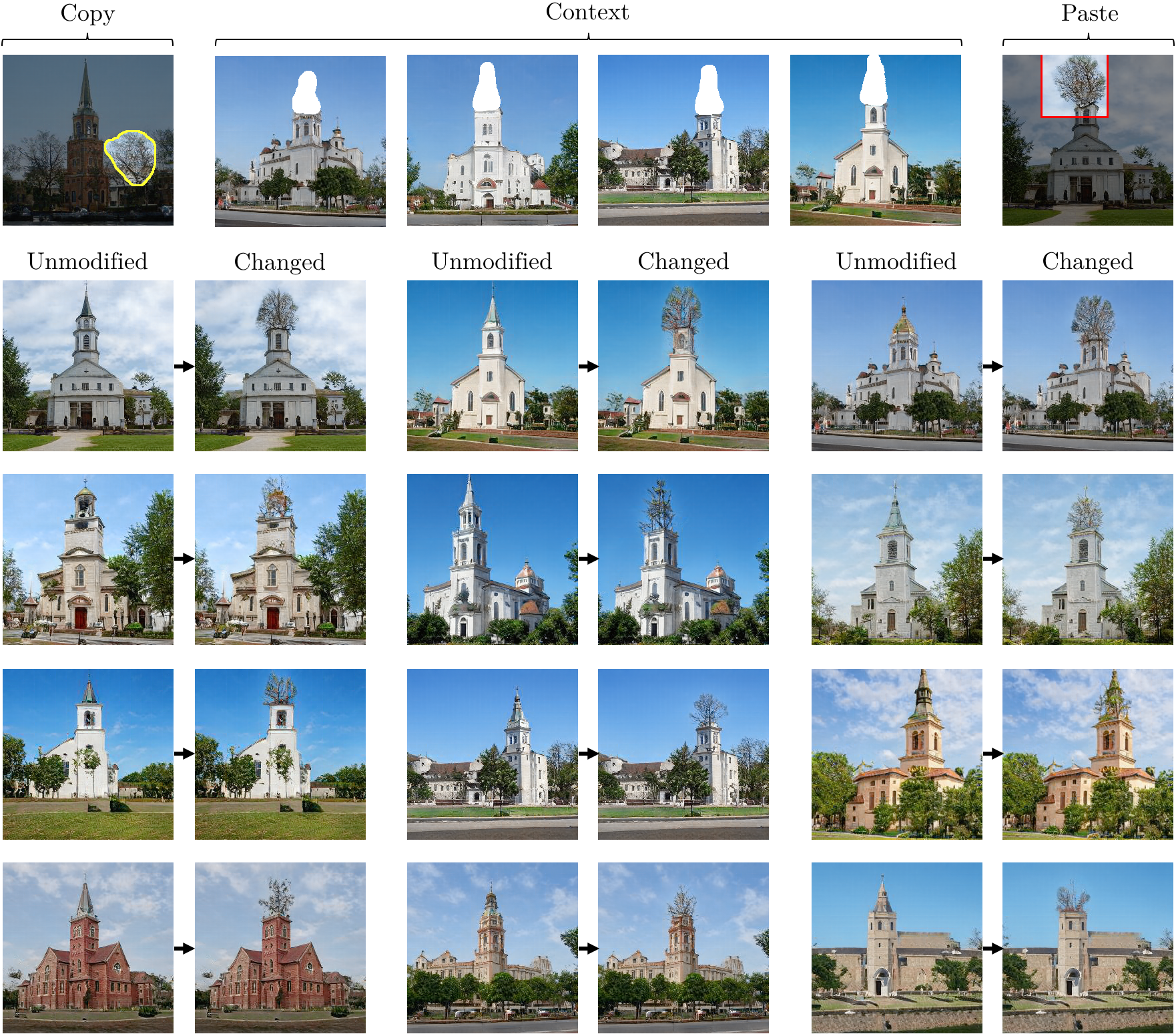
Example Results
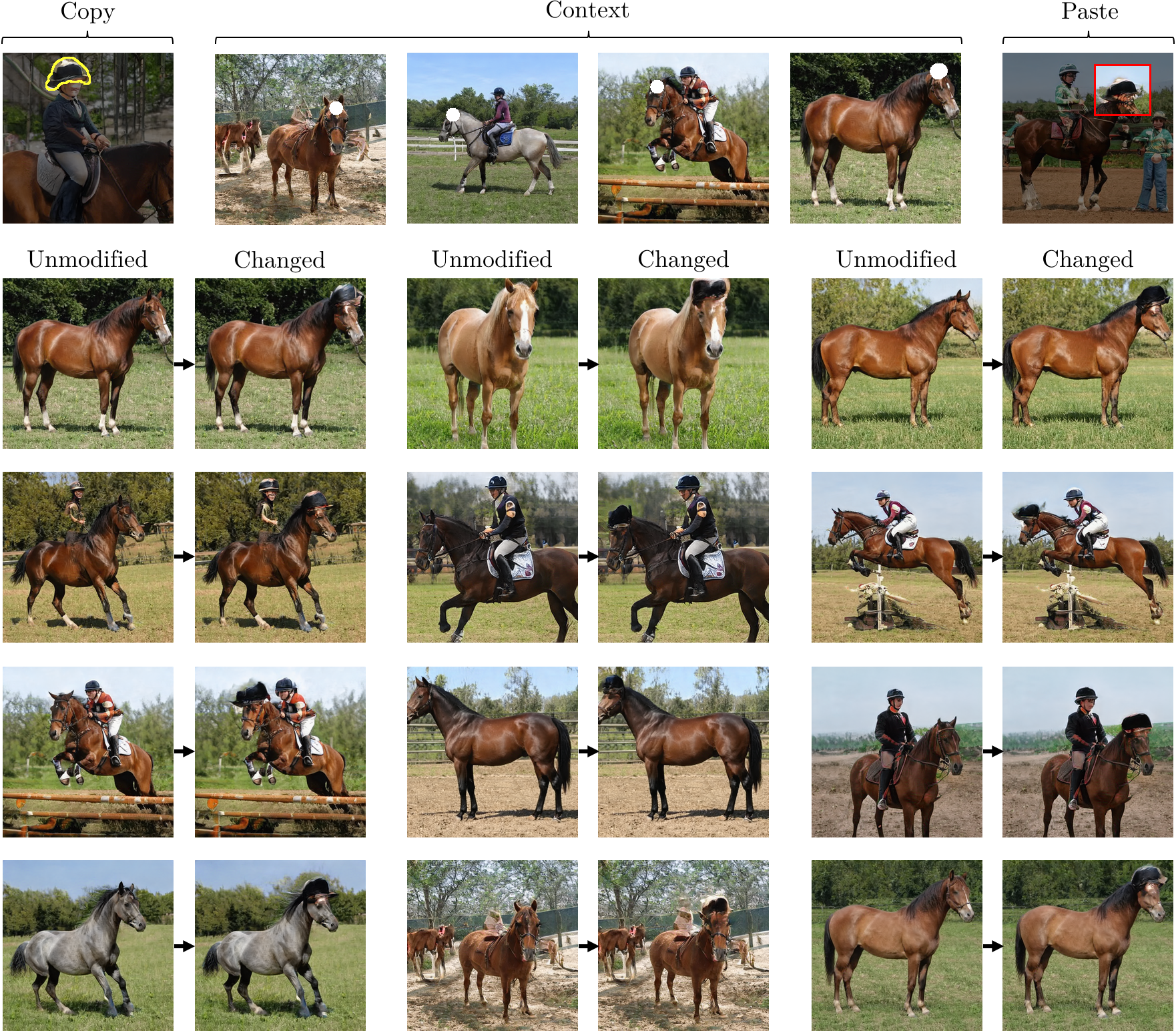
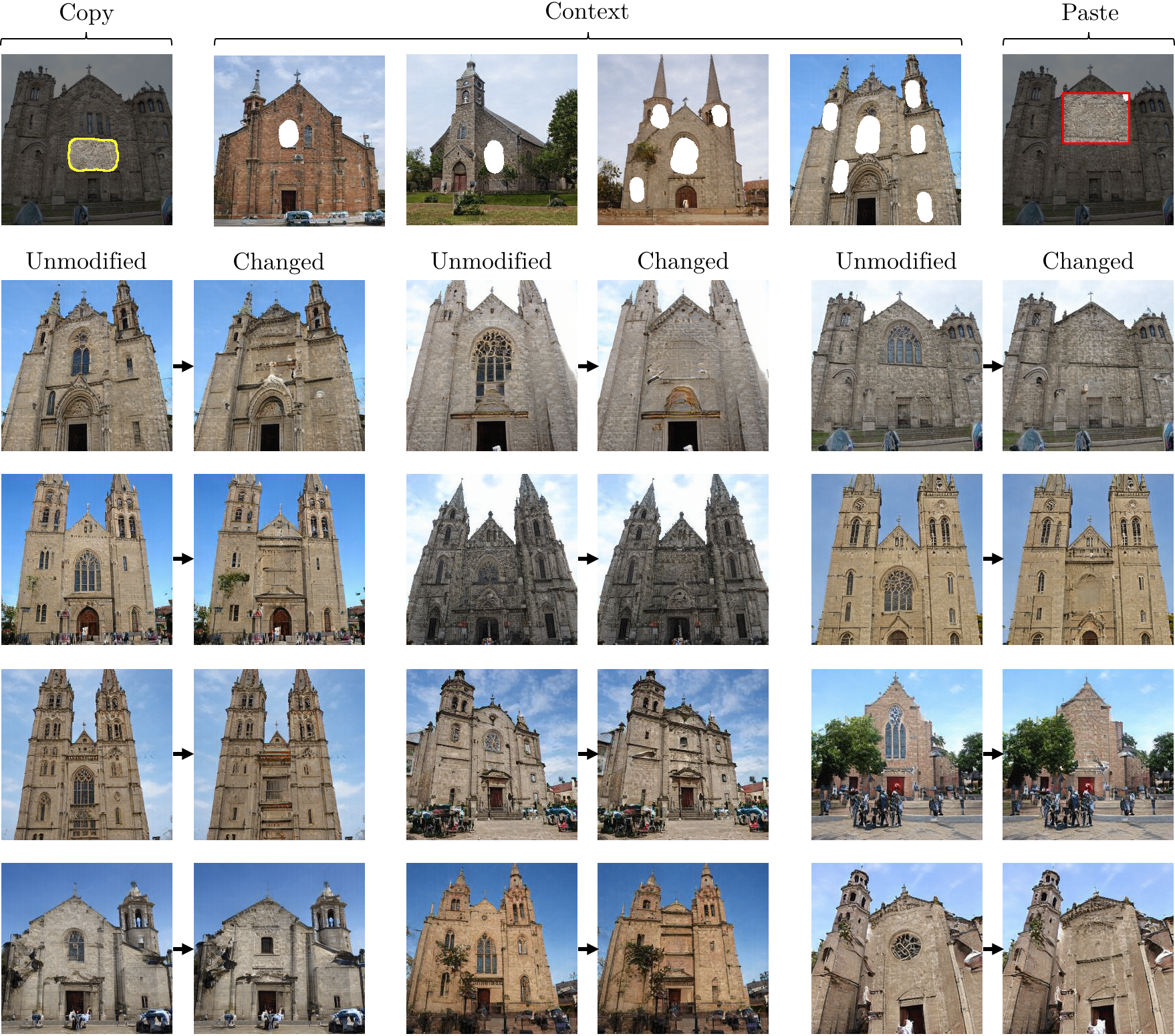
The results below show changes of a single rule within StyleGANv2. In each case, four examples chosen by the user (center of the top row) establish the context for the rule begin rewritten, and the "copy and paste" examples (left and right of top row) indicate how the user wishes to change the model.
The grid below shows pairs of outputs: for each pair, the first is the output of the original unmodified StyleGANv2. The second is the output of the modified StyleGANv2, applying the user's intention using our method.
First: changing the rule defining kids' eyebrows to make them look like a bushy mustache.
Altering the rule for pointy tower tops to make them into trees.
Changing the rule for tops of horses heads, to put hats on horses.
Changing the rule for drawing frowns into one to draw smiles.

Removing the main window in a building by changing the rule to draw a blank wall.
How to Cite
bibtex
@inproceedings{bau2020rewriting,
title={Rewriting a Deep Generative Model},
author={Bau, David and Liu, Steven and Wang, Tongzhou and Zhu,
Jun-Yan and Torralba, Antonio},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2020}
}